Inside the Zeon Stack
Brontë Kolar

Every new material, every drug candidate, every battery chemistry eventually comes down to someone running an experiment and measuring what happens. AI can propose what to try next. Simulations can narrow the search. But the knowledge that moves a field forward - that actually changes what we know about how the world works - comes from the physical world. And right now, that's where everything bottlenecks.
This post is the full picture of how we solve that: how the robot sees, how it reasons, and how scientists and agents tell it what to do. If you've been following our launches on X, consider this the director's commentary.
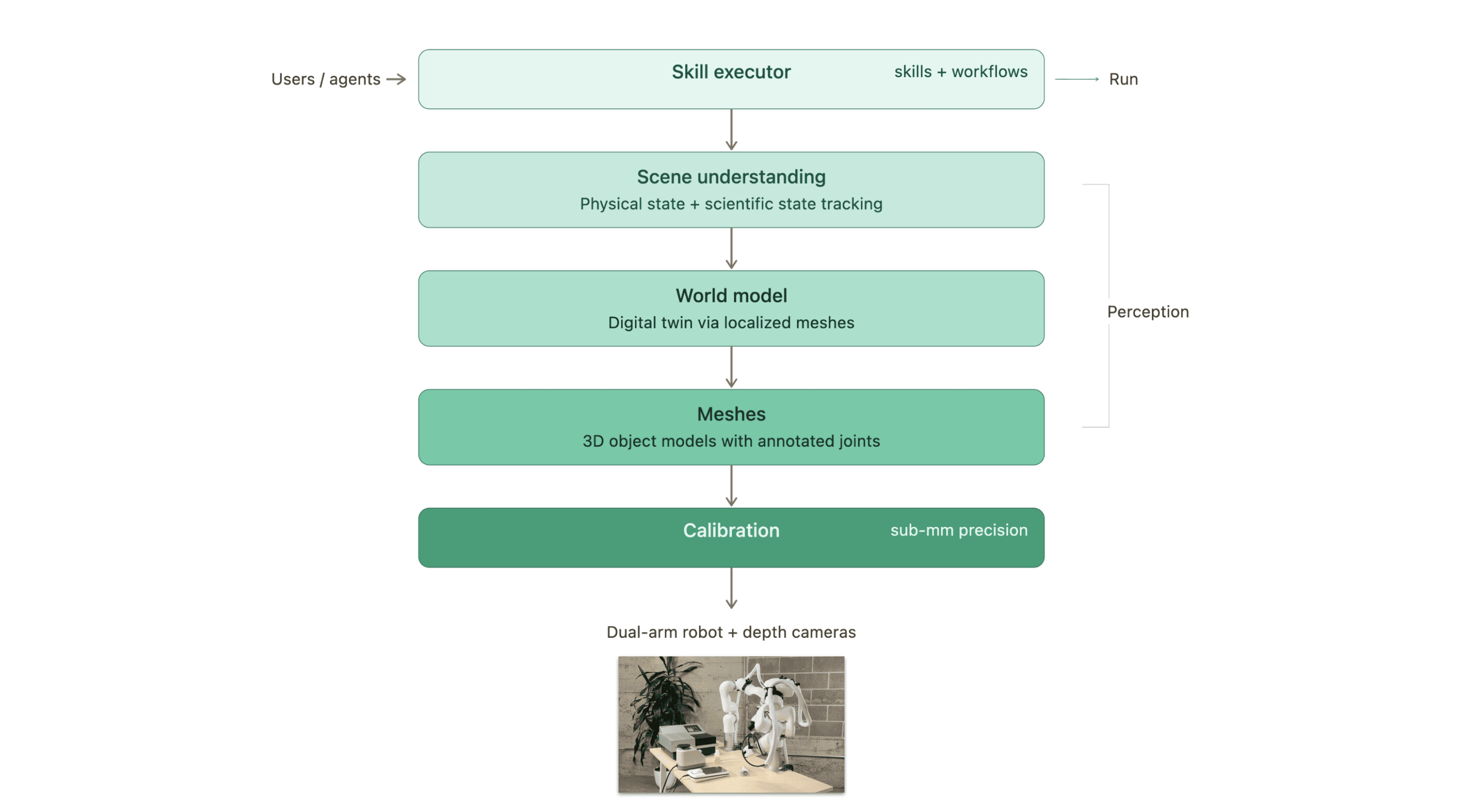
Every component of our system, from how the robot sees objects to how it plans motion to how users define workflows, is designed for environments that change. This post walks through the full stack, top to bottom.
Watch the full system in action
Precision First: Why Calibration Is the Hardest Easy Problem
Lab automation demands sub-millimeter precision. Inserting a microcentrifuge tube into a rack, placing a plate onto a reader, loading tubes into a centrifuge - these tasks have essentially zero tolerance for positional error.
Calibration is what makes this possible. It resolves exactly where cameras and robot arms are relative to the world and to each other. It sounds straightforward, but getting it robust enough for daily use in a real lab - where things get bumped, cameras drift slightly, and no two setups are identical - took significant engineering effort.
Everything downstream depends on this. If calibration is off, the best perception and planning in the world won't save you.
Seeing the Lab: Meshes Over Pixels
A robot that can only use pre-programmed equipment isn't useful in a real lab. The system needs to work with any machine, any labware, any layout.
To make that possible, we represent every object as a 3D mesh - a geometric model built from depth camera data. Meshes give us explicit geometry for collision avoidance, grasp planning, and spatial reasoning, and they're stable across lighting changes and visual noise.
We tried the pixel-only route first. Multiple times, actually. RGB-based approaches kept falling apart in real conditions - reflective surfaces, changing light, cluttered benches. Depth-based meshes solved these problems definitively.
But raw geometry isn't enough on its own. Lab equipment has moving parts - lids, doors, rotors, drawers. So we built annotation tools that let anyone mark joints, buttons, and articulated components on a mesh. These annotated models go into a shared library that grows over time. When a new piece of equipment shows up in the lab, someone scans it, annotates it, and the robot can work with it.
The World Model: A Living Digital Twin of the Lab
Individual meshes describe objects. The world model describes the lab.
We scan the full scene with depth cameras, then use a localization pipeline to place each object's mesh into a shared coordinate frame. The result is a structured digital replica of the physical workspace - every instrument, every plate, every rack, positioned accurately.
This works well for lab environments specifically because they're constrained. The set of objects is finite, we have accurate models of each one, and we don't need to solve open-world perception. We can exploit that constraint to build something much more precise and reliable than a general-purpose scene understanding system would give us.
The world model serves three critical functions. First, it drives motion planning - both arms plan paths around real geometry, not approximations. Second, it tracks physical state changes by continuously re-localizing articulated parts. When a centrifuge lid opens, the model updates. When a tray slides out, the planner knows. Third, when the robot picks up an object, that object attaches to the robot's model so the planner accounts for it during subsequent moves.
Building world models from real lab scenes
Keeping Up with Reality: State Tracking
A static world model would be useless in a real lab. The environment changes constantly during a protocol, and the robot needs to keep up.
We track state at two levels.
Physical state covers the mechanical configuration of equipment. Centrifuge lids open and close. Instrument doors swing. Plate readers have trays that extend and retract. Our parallelized localization algorithms continuously track these moving components so the simulation always reflects the current state of the lab - down to the position of a partially open lid. This keeps motion planning safe and accurate even as the workspace reconfigures itself throughout a run.
Scientific state covers what matters to the experiment. Tubes, plates, and reagents are persistent entities in the system. The robot knows where samples are, which instruments they've visited, and what's happened to them. When a plate moves from a thermal cycler to a reader, the system's understanding of the experiment updates accordingly. This is what lets workflows execute reliably across multi-step protocols rather than just performing isolated pick-and-place operations.
Both arms reason about the same live scene simultaneously, enabling coordinated dual-arm manipulation - one arm opens a machine while the other loads it, both planning around the same continuously updated model.
There's still a long way to go in fully capturing scientific state, but even the current system provides enough context for the workflows we're running today.
From Intent to Execution: Skills, Workflows, and the Executor
All of the perception and planning infrastructure exists to serve one goal: letting people (and agents) get work done.
The execution layer is built around two concepts: skills and workflows. A skill is a reusable robot capability assembled from low-level primitives - "pick up an object," "open a machine," "pipette into a well." A workflow composes skills into a complete protocol.
The authoring process is designed to be fast and safe. You write or describe the workflow, preview it in simulation to verify the sequence, then deploy it to the real robot. Because the world model stays synchronized with reality through live localization, workflows are resilient to environmental changes. If someone moves the vortexer between runs, the system finds it and adapts - no reprogramming required.
Everything is Python-based and inspectable. Skills, workflows, and world models are code, not black boxes. Engineers and AI agents can read them, modify them, and reuse them across experiments. The goal is to accumulate a library of capabilities that compounds over time, not a pile of one-off scripts that each solve a single protocol.
We recently demonstrated this by teaching the robot to vortex a full rack of tubes - authored from natural language in minutes, then executed deterministically.
The skill executor and workflow system
Why We Built the Full Stack
Lab robotics sits in an unusual spot. The environment is constrained enough to model accurately, but dynamic enough that rigid automation breaks. Solving that requires tight coupling between every layer of the stack, from depth sensing through to workflow execution. That's what we built, and it's what makes the system work reliably in real labs rather than just in demos.
We're building the execution layer for AI-driven science. If you're developing AI agents, automated experiment platforms, or lab-of-the-future infrastructure and need a way to run things in the physical world: get in touch.